
人工知能 (AI) は、かつてない規模の時代を迎えています。1兆パラメーターの大規模言語モデル(LLM)のトレーニングからリアルタイムのマルチモーダル推論の実現まで、AI ワークロードはデータセンターインフラストラクチャの基盤そのものを再構築しています。GPUとアクセラレータはAI の顔となっていますが、重大なボトルネックは舞台裏にあります。メモリ、帯域幅、遅延、スケーラビリティの課題が、AI システムの成功や限界を左右することがよくあります。そこで、コンピュート・エクスプレス・リンク(CXL)が活躍し、変革をもたらすソリューションを提供します。
AI のメモリーボトルネック
AI のメモリーボトルネックの主な原因は次のとおりです。
- トレーニング基盤モデルには膨大なメモリー容量が必要で、多くの場合、単一の GPU で利用可能な容量を超えます。
- 大規模な推論では、GPU 間でメモリを重複させることなく、大規模なデータセットに迅速にアクセスする必要があります。
- 従来のアーキテクチャでは、CPU、GPU、アクセラレータがサイロ化された状態で運用され、非効率性が生じます。
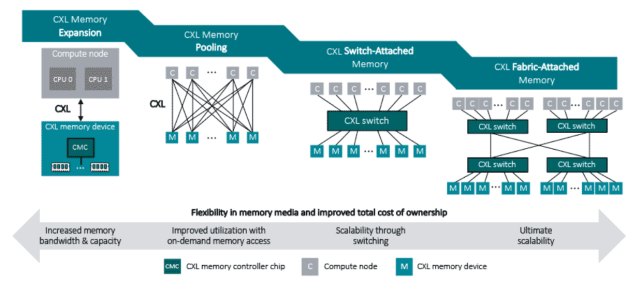
図1に示すように、サイロ化されたアーキテクチャでは、各CPUまたはGPUがそれぞれ独立したメモリーに接続されているため、容量が十分に活用されないことがよくあります。CXL プーリングでは、すべてのプロセッサが統一された共有メモリー空間にアクセスできます。このシフトにより、AI やデータ集約型のワークロードの柔軟なスケーリング、利用率の向上、パフォーマンスの向上が可能になります。
CXL はどのようにして解決するのか
コンピュート・エクスプレス・リンクは、特にAI とハイパフォーマンスコンピューティングにおける最新のワークロードのパフォーマンスとスケーラビリティの要求の高まりに対応するために作成された、オープン業界標準インターコネクト です。汎用 I/O 向けに最適化された PCIe (Peripheral Component Interconnect Express) とは異なり、CXL は CPU、GPU、アクセラレータ、およびメモリーデバイスを低レイテンシーかつフルキャッシュコヒーレンシで接続するように特別に設計されているため、異種プロセッサ間でデータの同期が保たれます。CXL は、従来のデバイスからホストへの通信を拡張することで、コンピューティングリソースとメモリーリソースをシステム全体またはサーバーのクラスター全体でシームレスに共有できるユニファイドファブリックを実現します。
CXL が導入する最も影響力のある機能の1つは メモリプーリングです。これにより、メモリーを単一の CPU または GPU に静的にバインドするのではなく、ワークロードのニーズに基づいてさまざまなデバイスに動的に割り当てることができます。そのため、孤立した容量がなくなり、メモリーリソースの使用率を高めることができます。もう 1 つの重要な機能は階層型メモリーです。この階層型メモリーでは、速度、容量、コスト効率のバランスが取れた DDR5 やパーシステントメモリーなどの CXL 接続メモリーのプールを増やすことで、高パフォーマンスのローカルDRAMを補完できます。最後に、CXL はコンポーザブル・インフラストラクチャの基礎です。CXLでは、大規模な言語モデルのトレーニングから遅延の影響を受けやすい推論タスクの実行まで、変化するワークロードの要求に合わせてコンピューティング、アクセラレータ、メモリーなどのリソースをリアルタイムでアセンブルおよび再構築できます。
つまり、CXL は、静的でサイロ化されたアーキテクチャから柔軟なファブリックベースのコンピューティングへの移行を意味し、次世代のAI とデータ集約型システムへの道を開きます。
テーブル 1. AI インフラストラクチャのレイテンシー、コヒーレンシー、スケーラビリティに関するPCIeとCXL の比較表:
CXL がAI インフラストラクチャにとって重要な理由
- 大規模言語モデル — CXL はノード間のメモリープールを可能にし、コストのかかるメモリー複製の必要性を減らします。
- マルチ GPU 推論 — 共有メモリープールは導入を簡素化し、インフラストラクチャのオーバーヘッドを削減します。
- コンポーザブルなAI データセンター — CXL はメモリーをオーバープロビジョニングする代わりに、柔軟なスケーリングを可能にします。

図2に示すように、CXL メモリープーリングでは、複数のGPUがユニファイドメモリープールを共有できるため、大規模な言語モデルの効率的なスケーリングが可能になります。
これからの道のり:CXL 3.0 とその先
CXL 3.0により、業界は段階的な改善にとどまらず、データセンターアーキテクチャの根本的な変化へと移行しつつあります。CXL 3.0では、ファブリック・トポロジ、マルチレベル・スイッチング、ホスト間でのコヒーレント・メモリー共有を導入することで、サーバー・ラック全体を統一された柔軟なAI ファブリックとして機能させることができます。これは、従来のGPUアイランドがメモリー制限によって制約され、複雑なモデル並列処理を余儀なくされる、大規模言語モデルなどのAI ワークロードにとって特に重要です。
複数のGPUからアクセスできる共有のコヒーレントメモリープールにより、学習が速くなり、重複が減り、大規模なモデルをより効率的にサポートできるようになります。ハイパースケーラー、クラウドプロバイダー、HPC施設はすでにCXL対応の導入を試験的に実施しており、Intel、AMD、SamsungやHPEなどのベンダーがロードマップにサポートを組み込んでいます。さらに将来を見据えて、CXL は、より高速な相互接続、よりきめ細かな構成可能性、プールメモリー向けにネイティブに最適化されたAI フレームワークへと進化すると予想されます。
要約すると、CXL 3.0は、サーバー中心のコンピューティングからファブリック中心のAIインフラストラクチャへの転換点であり、次世代のスケーラブルなAI およびLLMシステムの基盤を築くピボットポイントです。
テーブル 2. AI 固有のユースケースを含むCXL の進化(1.0→2.0→3.0)のタイムライン:
CXL がミッシング・リンクを解消
AI の未来は GPU だけにかかっているわけではありません。メモリーの接続、共有、スケーリング方法を再考する必要があります。 CXL は、孤立したリソースを一貫性のある柔軟なAI インフラストラクチャに変えるという、ミッシング・リンクを解消します。 AI インフラストラクチャコミュニティにとって、CXL は単なるテクノロジーではなく、次世代のデータセンターを構築するための 基盤 を表しています。
SMART Modular Technologiesは、統合メモリソリューションの設計、開発、高度なパッケージングを通じて、世界中のお客様がAI とハイパフォーマンスコンピューティング(HPC)を実現できるよう支援します。当社のポートフォリオは、 CXL のような最先端のメモリテクノロジー から、標準およびレガシーのDRAMやフラッシュストレージ製品まで多岐にわたります。30 年以上にわたり、当社は成長著しい市場における多様なアプリケーションのニーズに応える、標準、高耐久性、そしてカスタムのメモリーおよびストレージソリューションを提供してきました。 詳細については、今すぐお問い合わせください。



