
Artificial intelligence (AI) is entering an era of unprecedented scale. From training trillion-parameter large language models (LLMs) to enabling real-time multimodal inference, AI workloads are reshaping the very foundations of data center infrastructure. While GPUs and accelerators have become the face of AI, a critical bottleneck lies behind the scenes: memory, bandwidth, latency, and scalability challenges often determine the success or limits of AI systems. This is where Compute Express Link (CXL) steps in, offering a transformative solution.
The Memory Bottleneck in AI
These are some of the key items creating the memory bottleneck in AI:
- Training foundation models require enormous memory capacity, often exceeding what is available in a single GPU.
- Inference at scale demands rapid access to large datasets without duplicating memory across GPUs.
- Traditional architectures force CPUs, GPUs, and accelerators to operate in silos, creating inefficiencies.
As per figure 1, in siloed architectures, each CPU or GPU is tied to its own isolated memory, often leaving capacity underused. With CXL pooling, all processors can access a unified shared memory space. This shift enables flexible scaling, better utilization, and improved performance for AI and data-intensive workloads.
How CXL Comes to the Rescue
Compute Express Link is an open-industry standard interconnect created to address the growing performance and scalability demands of modern workloads, especially in AI and high-performance computing. Unlike PCIe (Peripheral Component Interconnect Express), which is optimized for general-purpose I/O, CXL is specifically designed to connect CPUs, GPUs, accelerators, and memory devices with low latency and full cache coherency, ensuring that data remains synchronized across heterogeneous processors. By extending beyond traditional device-to-host communication, CXL enables a unified fabric where computing and memory resources can be shared seamlessly across an entire system or even a cluster of servers.
One of the most impactful capabilities CXL introduces is memory pooling, which allows memory to be dynamically allocated to different devices based on workload needs rather than being statically bound to a single CPU or GPU. This eliminates stranded capacity and enables higher utilization of memory resources. Another key feature is tiered memory, where high-performance local DRAM can be complemented by larger pools of CXL-attached memory—such as DDR5 or persistent memory—delivering a balance of speed, capacity, and cost efficiency. Finally, CXL is a cornerstone for composable infrastructure, where resources like compute, accelerators, and memory can be assembled and reassembled in real time to match shifting workload demands, from training massive, large language models to running latency-sensitive inference tasks.
In short, CXL represents a shift from static, siloed architectures towards flexible, fabric-based computing, paving the way for next-generation AI and data-intensive systems.
Table 1. Comparison table between PCIe vs. CXL in terms of latency, coherency and scalability for AI infrastructure:
Why CXL Matters for AI Infrastructure
- Large Language Models – CXL enables memory pooling across nodes, reducing the need for costly memory duplication.
- Multi-GPU Inference – shared memory pools simplify deployment and reduce infrastructure overhead.
- Composable AI Data Centers – instead of over-provisioning memory, CXL allows flexible scaling.

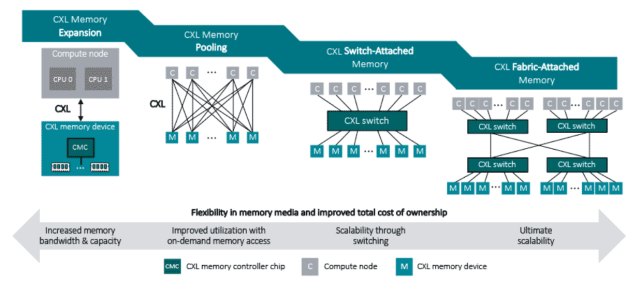
As per figure 2, CXL memory pooling allows multiple GPUs to share a unified memory pool, enabling efficient scaling of large language models.
The Road Ahead: CXL 3.0 and Beyond
With CXL 3.0, the industry is moving beyond incremental improvements to a fundamental shift in data center architecture. By introducing fabric topologies, multi-level switching, and coherent memory sharing across hosts, CXL 3.0 allows entire racks of servers to function as a unified, flexible AI fabric. This is especially significant for AI workloads such as large language models, where traditional GPU islands are constrained by memory limits and forced into complex model parallelism.
With shared, coherent memory pools accessible across GPUs, training becomes faster, duplication is reduced, and larger models can be supported more efficiently. Hyperscalers, cloud providers, and HPC facilities are already piloting CXL-enabled deployments, with vendors from Intel and AMD to Samsung and HPE building support into their roadmaps. Looking further ahead, CXL is expected to evolve toward even faster interconnects, finer-grained composability, and AI frameworks natively optimized for pooled memory.
In summary, CXL 3.0 is a pivot point—from server-centric computing to fabric-centric AI infrastructure—laying the foundation for the next generation of scalable AI and LLM systems.
Table 2. Timeline of CXL evolution (1.0 → 2.0 → 3.0) with AI-specific use cases:
CXL Provides the Missing Link
AI’s future depends on more than GPUs—it requires rethinking how memory is connected, shared, and scaled. CXL provides the missing link, transforming isolated resources into a coherent, flexible AI infrastructure. For the AI infrastructure community, CXL represents not just technology, but a foundation for building the next generation of data centers.
SMART Modular Technologies helps customers around the world enable AI and high-performance computing (HPC) through the design, development, and advanced packaging of integrated memory solutions. Our portfolio ranges from today’s leading edge memory technologies like CXL to standard and legacy DRAM and Flash storage products. For more than three decades, we’ve provided standard, ruggedized, and custom memory and storage solutions that meet the needs of diverse applications in high-growth markets. Contact us today for more information.




