Full-Stack AI
Factory Platform
Our AI Factory Platform combines five core elements with industry-leading partner technologies to help customers confidently deploy and scale AI workloads with speed and precision.
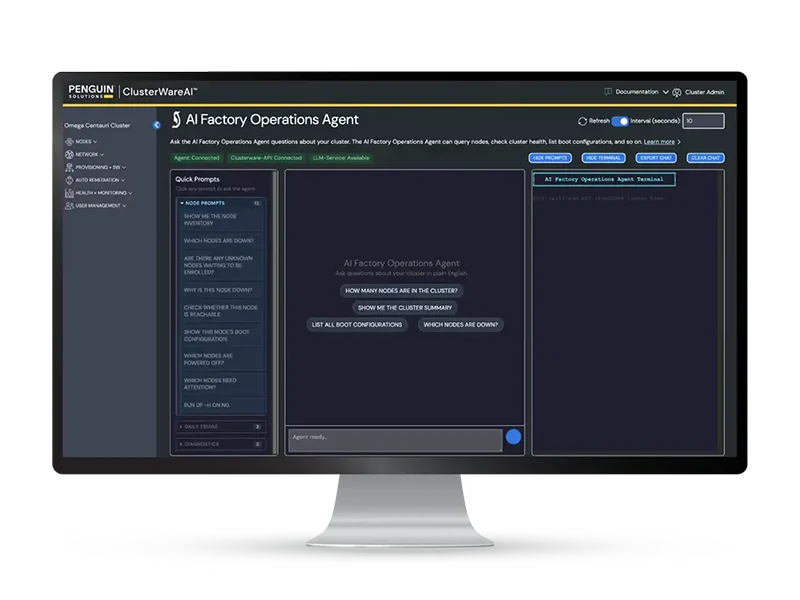
AI factory platform operating system software that unifies and automates cluster deployment and management to simplify operations, streamline administration, and optimize performance.
Memory solutions designed specifically for data centers and AI inference. Together, they optimize performance, improve efficiency, and support the growing demand for inference and agentic AI.
Advanced computing systems and infrastructure elements optimized for AI workloads. Built for scalability and performance, these solutions support AI training, inference, and data-intensive applications.
Validated AI factory reference designs and scalable full-stack AI training and inference solutions. Designed to accelerate deployment, scale efficiently, and optimize performance across AI environments at scale.
Expert support across the full AI lifecycle, including design, build, deployment, and managed services. Penguin Solutions helps customers confidently deploy, optimize, and scale AI environments with speed and precision.