
In many real-world inference environments, GPUs can spend more time waiting on data than doing math—utilization can sit around 30% even when the model and kernels are well tuned.
Penguin Solutions is tackling this “memory wall” with a practical architecture built around two ideas: treat the transformer key–value (KV) cache as a first-class memory workload, and scale memory capacity independently using CXL® (Compute Express Link®). By offloading and tiering KV cache—especially the colder portions that don’t need to live in high bandwidth memory (HBM)—systems can increase concurrency, support longer contexts, and improve overall GPU efficiency without buying compute just to buy memory.
The Memory Wall in AI inference
Inference bottlenecks are increasingly dominated by data movement. Several trends are converging to push memory demand faster than GPU memory budgets: model sizes continue to grow (increasing the footprint of weights and intermediate activations), prompts are longer (documents, codebases, images, and multimodal context), multi-turn chats accumulate history, and KV cache requirements expand with both prompt length and the number of concurrent sessions.
As the industry transitions toward inference-dominated workloads, the implication is clear: solving the memory wall is central to the economics of deploying AI at scale.
Understanding AI Training vs. AI Inference (and where KV Cache Fits)
Training starts from an untrained neural network and repeatedly adjusts parameters using large batches of data. It is throughput-oriented and typically amortizes expensive setup over long runs.
Inference is the serving phase: the trained model performs work for end users. For large language models, that usually means predicting the next token, then the next, and so on. This token-by-token generation loop is where KV cache becomes critical, because each new token must attend over the full context that came before it.
What is KV Cache?
In transformer attention, each token contributes “keys” and “values” used to compute attention for subsequent tokens. During inference, recomputing keys and values for the full prompt at every decode step would be prohibitively expensive. KV cache avoids that by storing the pre-computed keys and values for the prompt prefix. After the initial prefill pass computes those states once, later decode steps can reuse them while generating new tokens.
KV Cache in Action
Suppose you ask a model, “What is the capital of France?” The request begins with tokenization, where the prompt is converted into token IDs. Those tokens then pass through an embedding layer that maps them into vectors while encoding both meaning and position—so, for instance, the model can distinguish “France” as the semantically important entity in the sentence.

Next comes the transformer’s compute-intensive prefill phase, which produces the attention states for the prompt and populates the KV cache. After that, the model enters the decode loop, emitting output tokens one at a time. Crucially, it does not need to rerun the full prompt through attention each time; it can reuse cached keys and values and only compute the incremental work for the next token. Finally, detokenization converts the output token IDs into readable text (e.g., “Paris is the capital.”).
The compute savings are immediate: KV cache turns repeated full-prompt recomputation into a one-time prefill cost plus cheap incremental decode steps.
Cache Hits: the Second Major Benefit
KV cache optimization doesn’t stop at single-query efficiency. Real workloads often contain shared prefixes—long system prompts, repeated instructions, repeated retrieval context, and multi-turn chat history. When a user asks a follow-up question, or when many users ask similar questions, significant portions of the cached prefix can be reused.
This shows up in common production patterns: multi-turn conversations where users build on prior context; concurrent users asking structurally similar questions (for example, many variants of the same template query); and document analysis workflows where the same large document is referenced across many requests. As prompts reach thousands—or tens of thousands—of tokens, cache reuse becomes a first-order driver of throughput and cost.
The Traditional Approach: Storing KV Cache in HBM (and Why It Breaks)
Most inference stacks store KV cache in GPU HBM because it is fast. Even with modern accelerators—for example, NVIDIA B200-class GPUs with up to 192 GB of HBM—HBM remains a scarce resource. It must hold model weights for fast access during matrix operations, intermediate activations, and the KV cache itself.
As concurrency rises and contexts expand, KV cache pressure quickly consumes remaining headroom. Some frameworks spill overflow to CPU memory, but that can degrade latency and throughput. The conventional scaling response is to add more GPU nodes. It works, but it is an expensive way to buy memory, because you are forced to purchase additional compute alongside it. What operators need instead is the ability to scale memory capacity more independently and more economically.
CXL: Enabling Memory Disaggregation
CXL makes memory expansion more modular by attaching memory devices over the PCIe bus. In practical terms, it allows systems to add large pools of memory beyond traditional motherboard DIMM capacity, and it opens the door to disaggregated architectures where memory can be provisioned as a shared resource.
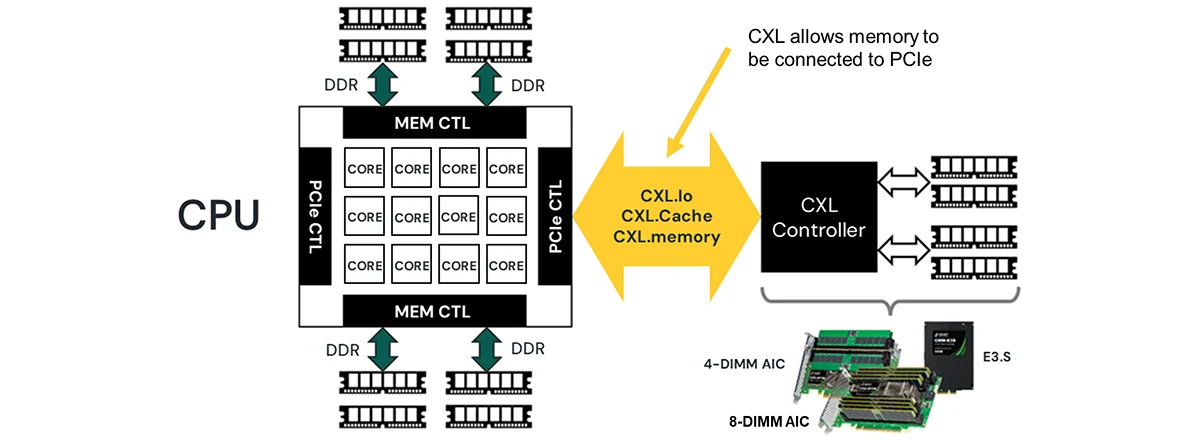
Penguin Solutions has developed CXL memory expansion products, including an eight‑DIMM add‑in card (AIC) that can support up to 1 TB of memory per card. In the Penguin Solutions MemoryAI™ KV Cache Server, this approach scales to approximately 11 TB of total memory: about 8 TB from CXL add‑in cards plus about 3 TB of system memory. That capacity is not meant to replace HBM; it is meant to complement it by absorbing the colder portions of the KV cache that would otherwise force GPU scaling.
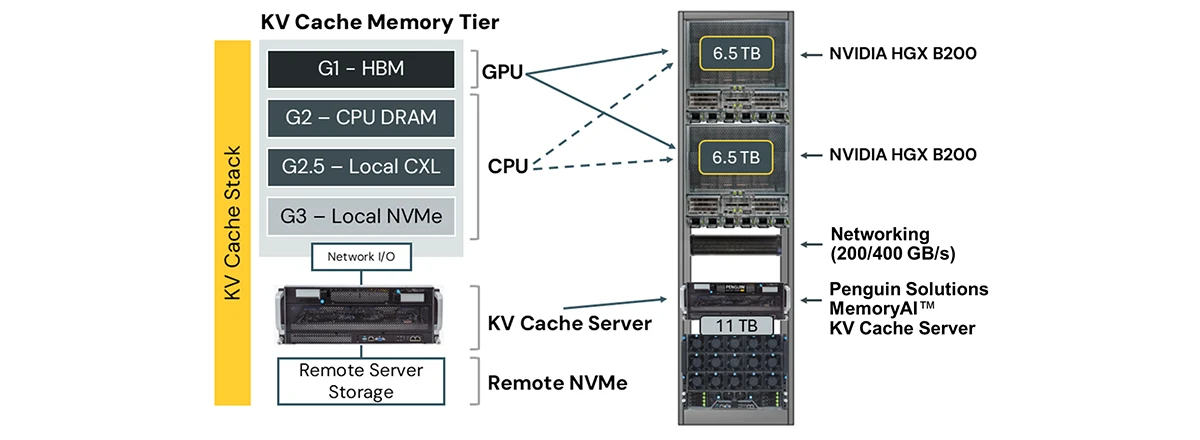
NVIDIA’s KV Cache Memory Tier Hierarchy
Offloading KV cache requires ecosystem support, and NVIDIA has articulated a tiered hierarchy for where KV cache can live—each tier trading off performance, capacity, and cost.

KV Cache Hierarchy
Conceptually, this forms a performance–cost pyramid. The goal is to keep the active working set in HBM, then progressively spill colder KV cache to larger, cheaper tiers while preserving predictable serving performance.
G1: GPU HBM
At the top is G1: GPU HBM, where hot, latency-critical KV cache for active generation belongs.
G2: CPU DRAM
Next is G2: CPU DRAM, which can serve as a staging area and buffer—lower latency than external storage with moderate capacity.
G2.5: Local CXL
NVIDIA also describes a middle tier often labeled G2.5: local CXL within a compute node, balancing capacity and latency at a lower cost per GB than HBM.
G3: Local NVMe
Below that is G3: local NVMe, which provides high capacity but higher latency and is better suited for warm KV cache reused over shorter timescales.
G4: Remote Storage
Finally, G4 covers remote shared storage for cold artifacts—network-attached resources such as remote CXL (including a KV Cache Server) and remote NVMe—offering the largest capacity and lowest cost per GB, at the expense of the highest latency.
MemoryAI KV Cache Server from Penguin Solutions
Penguin Solutions' MemoryAI KV Cache Server operationalizes the remote (G4) tier by providing a rack-level pool of CXL-backed memory accessible over high-speed fabric. A typical rack configuration might include multiple NVIDIA HGX B200 compute nodes, 200 Gb/s or 400 Gb/s Ethernet or InfiniBand networking, and one or more MemoryAI KV Cache Servers (about 11 TB each).
To the inference stack, the cache server appears as remote memory that can hold large KV working sets beyond what fits in HBM.
Architecturally, the benefits follow directly from that decoupling: improved GPU utilization because compute is no longer stalled on memory pressure; higher concurrency because more sessions can be kept resident; longer usable context windows without imposing artificial limits; reduced infrastructure cost because memory capacity can scale without scaling GPU nodes; and lower power consumption because CXL memory expansion uses significantly less power than provisioning an equivalent amount of HBM.
Software Stack: Enabling KV Cache Offload
Hardware only helps if the software stack can place, retrieve, and route KV cache across tiers efficiently. Penguin Solutions has approached this in two parallel tracks: a proof-of-concept built from open-source components and a production integration aligned with NVIDIA’s inference platform direction.
Initial Implementation with Open-Source Tools
The Office of the CTO assembled an initial proof-of-concept using open-source components. vLLM provided an inference framework with KV cache management hooks, and custom scripting handled system discovery and provisioning: detecting CXL nodes, carving out RAM disks from CXL memory blocks, and exporting those disks to the inference environment. Redis served as a cache management layer for key-value lookup and coordination. Operationally, the SmartCXL utility supported CXL device firmware updates, health monitoring, and debugging. This path validated end-to-end KV cache offload to remote CXL memory and de-risked the architectural approach.
Production Path: NVIDIA Dynamo integration
The production-ready solution integrates with NVIDIA Dynamo, a comprehensive inference environment that includes standardized KV cache management and support for disaggregated prefill and decode. Dynamo’s architecture includes a KV cache block manager (KVBM) that separates memory management from model execution engines, standardizing storage access. It also includes a router/indexer that acts as a context-aware reverse proxy to direct requests to appropriate compute resources, plus KV publisher and KV indexer components to manage cache distribution and lookup across disaggregated resources.
Disaggregated Prefill & Decode
A key capability in this stack is disaggregated prefill and decode. Rather than having a single node handle both the compute-intensive prefill phase (tokenization, embedding, attention calculation) and the decode phase (iterative token generation), these stages can be distributed across specialized hardware pools. This improves hardware utilization because prefill and decode have different compute characteristics; increases throughput because multiple prefill workers can process incoming requests in parallel and feed decode workers; and enables shared cache access because both prefill and decode workers can read the same disaggregated KV cache without duplicating it.
Penguin Solutions is actively integrating its MemoryAI KV Cache Server with NVIDIA Dynamo and NIXL, with performance benchmarks expected by the end of by May 2026. Early testing by partners using similar approaches has demonstrated 67% lower latency with CXL-based cache offload compared to NVMe-based approaches, 87% cache hit rates in prefix-heavy workloads, 88% faster time-to-first-token for warm cache hits, and 2–4× throughput improvements through reduced cache fragmentation.
Software Tools & Management
The Penguin Solutions MemoryAI KV Cache Server includes management utilities designed for production operations: Linux system diagnostics, CXL firmware version tracking, detailed DIMM inventory, error injection for validation, and streamlined firmware update workflows. SmartCXL provides a unified interface for day-to-day monitoring and debugging across the CXL memory pool.

A typical KV cache integration workflow follows a practical sequence: detect and enumerate CXL resources, create CXL-backed RAM disks, export and manage those disks for the inference framework, configure access through the chosen protocol (for example, NVMe over Fabric, iSCSI, or direct memory access mechanisms), and then integrate with a cache manager such as Redis or Dynamo’s KV services.
Looking Forward: Building Smarter AI Infrastructure
KV cache disaggregation changes rack-level design. Instead of scaling inference clusters solely by adding more GPU nodes, architectures can separate concerns: compute-optimized nodes with NVIDIA GPUs run model execution, memory-optimized nodes (KV Cache Servers) provide large, cost-effective cache capacity, and a high-speed fabric connects them with minimal overhead. This optimizes both capital and operating expenditure by keeping GPUs productive while treating memory as a scalable, modular resource.
As language models continue to grow and context windows move toward millions of tokens, memory pressure will intensify. NVIDIA’s continued investment in KV cache tiering—alongside innovations like NVFP4 4-bit KV cache quantization—underscores a future where memory placement will matter as much as kernel-level optimization. Organizations deploying AI inference should evaluate their memory architecture with the same rigor they apply to compute.
Penguin Solutions’ MemoryAI KV Cache Server with SMART 1TB CXL Memory AICs offers a practical path to breaking through the memory wall and scaling inference more economically.
SMART Modular Technologies helps customers around the world enable AI and high-performance computing (HPC) through the design, development, and advanced packaging of integrated memory solutions. Our portfolio ranges from today’s leading edge memory technologies like CXL to standard and legacy DRAM and Flash storage products. For more than three decades, we’ve provided standard, ruggedized, and custom memory and storage solutions that meet the needs of diverse applications in high-growth markets. Contact us today for more information.

