
What is SafeDATA?
SafeDATA technology combines unique power loss detection and hold-up circuitries with an advanced controller firmware algorithm to flush in-flight data from volatile cache to NAND Flash memory in order to safeguard data against corruption and/or loss during the sudden power loss.
Why SafeDATA?

When power failures occur during system operations, drives can be corrupted and data is damaged. This results in downtime as drives must be reformatted, operating systems have to be reinstalled, and products could be returned for RMA.
Power loss protection technology is one of the most important value-added features and makes the biggest difference within the embedded SSDs. Truly RUGGED SSDs are equipped with both hardware and firmware architecture levels that could withstand aggressive power cycling.
How Does SafeDATA Work?
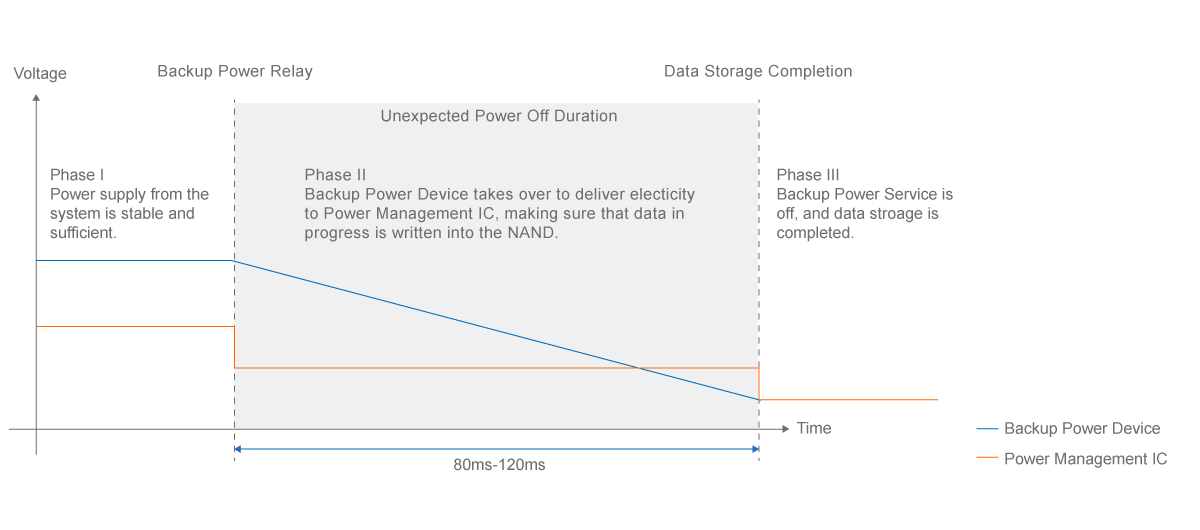
SMART’s SafeDATA technology ensures stable power supply for an extended period of time right after detecting unexpected power drop. Power Management IC plays an important role in sharing sufficient electricity with all the devices on board to make sure data is securely processed and stored from the DRAM cache to the NAND.
The average processing time from backup power relay to data storage completion usually takes about 40ms-60ms depending on computing complexity or size. SMART’s SafeDATA technology offers 80ms-120ms longer buffering time to strengthen data integrity in the event of power failure.
What is SafeStor?
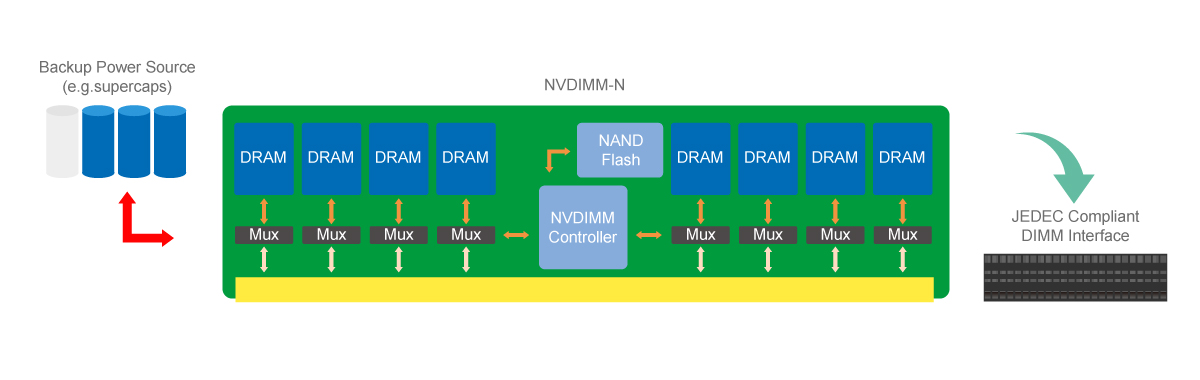
SMART’s DDR4 NVDIMM features proprietary SafeStor engine which employs multi-channel NAND Flash and high-speed switching circuitry to provide robust backup and restore capability, all while functioning as a JEDEC standard DDR4 RDIMM during normal operation.
Why SafeStor?
NVDIMMs are used for accelerating computing performance for the embedded storage platforms, such as enterprise storage, HPC, and machine learning. With SMART's SafeStor Technology, data that DRAM is processing will be moved to NAND Flash using supercaps for backup power during an unexpected power loss event. Once the power is returned, DRAM data is restored from NAND Flash, and supercaps are recharged in minutes.
How Does SafeStor Work?
SMART’s SafeStor supports the engine which initiates backup and restore operations upon command from the host controller as well as manages the NAND Flash interface. The SafeStor engine employs multi-channel fast NAND and high-speed switching circuitry to provide robust backup and restore capability, all while functioning as a JEDEC standard DDR4 RDIMM during normal operation.
Temporary power is provided to the NVDIMM during a sudden power loss (SPL) event by a hybrid supercap module, which can be tailored to individual application environments. SMART's expanded lineup of NVDIMMs features end-to-end error checking and correction capabilities to ensure a high level of data integrity during backup and restore operations.
What is Single Event Upset?
A Single Event Upset (SEU) is an inadvertent change in bit status occurring in a digital system when a high energy neutron or alpha particle randomly strikes causing a memory bit to flip states. These high-energy particles can originate from terrestrial or extra-terrestrial sources such as cosmic rays.
Why Single Event Upset?
SEU poses a serious and significant threat to electronic devices, particularly SSDs, by causing temporary errors due to cosmic rays from space or Alpha particles from radioactive impurities. These seemingly small errors can lead to major disruptions:
- High Annual Failure Rate (AFR): SEU can cause an AFR of up to 1.75%, impacting system uptime.
- Operational Interruptions: If the system cannot recover gracefully from an SEU that causes the system to hang, then it can lead to down time if the host has to reboot. In critical environments like data centers, telecom networks, and edge servers, these disruptions can lead to costly downtime and loss of productivity.
- Service Interruption: For devices in remote or hard-to-access locations, SEU-induced failures can require physical intervention, leading to significant service interruptions and increased maintenance costs.
How Does Single Event Upset Work?
SEU can lead to abnormal operation of digital systems or even total system failure. Addressing these errors, especially in systems that are difficult to reach or access, is crucial for ensuring recovery to normal operations. This is essential for maintaining reliable operations and uninterrupted runtimes of systems.
What is Advanced Error Detection & Correction?
SMART’s Advanced Error Detection & Correction technology reinforces the ECC (Error Code Correction) engine and utilizes RAID (Redundant Array of Independent Disks) mechanism. Data is reconstructed by the prior stored parity in other pages. The recovered data will be stored in a new block, and the prior stored block will be refreshed.
Why Advanced Error Detection & Correction?
As Flash memory moves to smaller geometries with the increase in the number of bits stored per cell, the error rate also increases. ECC shows inherent limits in checking the excessive increase in errors. Therefore, more powerful error correction algorithms are needed to ensure the reliability of the Flash storage device.
How Does Advanced Error Detection & Correction Work?
Advanced Error Detection & Correction provides additional protection over Standard ECC because it is possible to correct certain memory errors that would otherwise be uncorrected and result in a server failure.
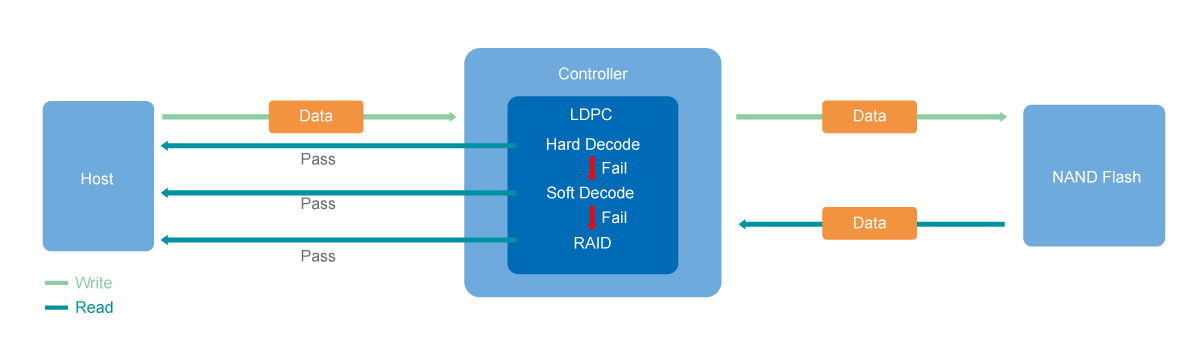
SMART's Advanced Error Detection & Correction mechanism comes with Low-Density Parity-Check (LDPC) codes to efficiently decode and correct errors in TLC NAND for higher stability and P/E cycles. RAID engine Data Recovery is used to recover and restore corrupted data from RAID drives and storage components.
What is End-to-End Data Protection?
End-to-End Protection ensures data is correctly transferred at every data transfer point within an SSD by utilizing Error Correction Code (ECC) and additional protection mechanisms, such as Cyclic Redundancy Check (CRC), to detect and rectify errors.
Why End-to-End Data Protection?
Errors are bound to happen during data transmission. As storage devices grow in size, the data corruption problem is getting bigger. Data gets corrupted all the time, sometimes you will not even notice it.
How Does End-to-End Data Protection Work?
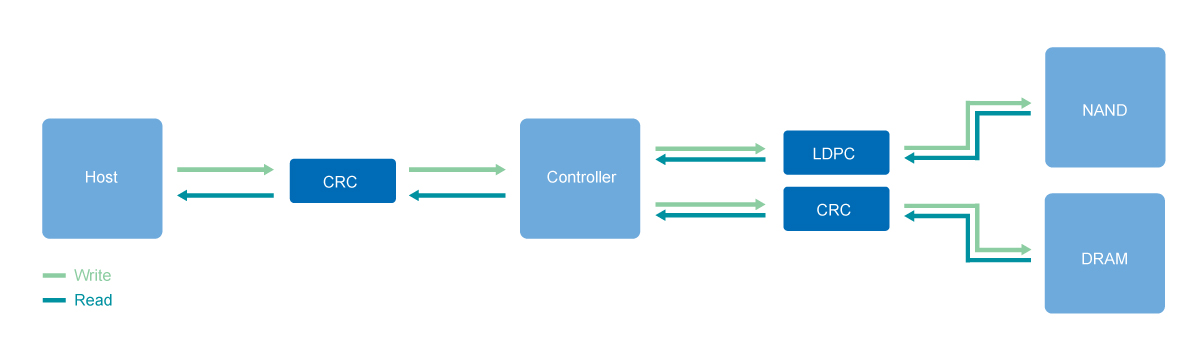
There are multiple data transfer points within an SSD. After the data reaches the controller from the host, it will be handled by either the embedded SRAM or the separate DRAM chip before being stored in the NAND Flash. Error Correcting Code (ECC) and Cyclic Redundancy Check (CRC) mechanisms are implemented at every data transfer point to detect and rectify errors seamlessly. Additionally, LDPC is implemented between the Flash and the controller buffer to efficiently decode and correct errors in TLC NAND for higher stability and P/E cycles.
What is Background Scan and Refresh?
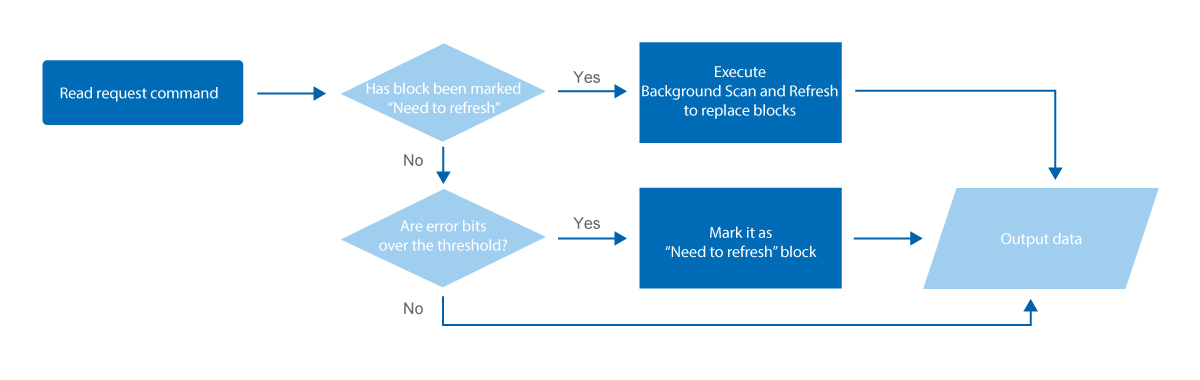
Background Scan and Refresh can count the times of block read and relocate cold data to fresh blocks to ensure the data is always stored in the healthy blocks.
Why Background Scan and Refresh?
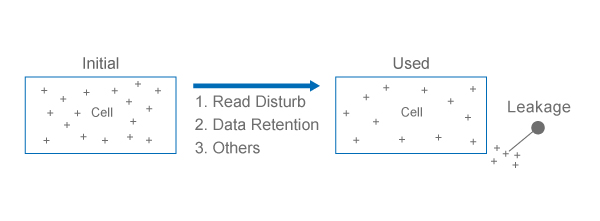
Performing very high number of read access on individual pages before an erase command for the block containing those pages can lead to read disturb errors. Read disturbs usually occurs when electrons are stored steadily in the cold zone of blocks and no data movements after thousands of times of data reading.
How Does Background Scan and Refresh Work?
SMART's Background Scan and Refresh plays a proactive role in avoiding read disturb errors from occurring. By counting the times of block read and relocating cold data to fresh blocks, SMART’s Background Scan and Refresh ensures the data is always stored in the healthy blocks.
What is S.M.A.R.T Flash Storage Monitoring?
Self-Monitoring, Analysis, and Reporting Technology (S.M.A.R.T.) is a self-monitoring system that prevents risks from unscheduled downtime by monitoring and displaying critical drive information.
Why S.M.A.R.T Flash Storage Monitoring?
The indicators includes the drive’s health, status, usage info and potential disk problems. Its primary function is to detect and report various indicators of drive reliability, or how long a drive can function while anticipating imminent hardware failures.
How Does S.M.A.R.T Flash Storage Monitoring Work?
When S.M.A.R.T. data indicates a possible imminent drive failure, software running on the host system may notify the user so action can be taken to prevent data loss, and the failing drive can be replaced without any loss of data.
SMART Modular Technologies helps customers around the world enable high performance computing through the design, development, and advanced packaging of integrated memory solutions. Our portfolio ranges from today’s leading edge memory technologies to standard and legacy DRAM and Flash storage products. For more than three decades, we’ve provided standard, ruggedized, and custom memory and storage solutions that meet the needs of diverse applications in high-growth markets. Contact us today for more information.



